
I recently hit this rather interesting issue when migrating a bunch of SQL Servers onto a nice, shiny new SAN.
The plan was simple enough, take the secondary servers in the four node cluster, migrate those over to the new SAN provided to me by the lovely storage guys. Once they were done, fail the AGs over and migrate the old primary server. Job done, simple!
Well apparently not.
Things started off well, the first couple of servers migrated just fine. But just then reports started coming in of performance problems in the application.
Looking at SQL, I could see a huge amount of HADR_SYNC_COMMIT waits on the primary server and the recovery queue on one of the secondary servers that we’d migrated just getting bigger and bigger. Availability Group synchronisation on the secondary server was falling behind. But why?
The answer was to be found in SQL’s error log.
There have been 27888384 misaligned log IOs which required falling back to synchronous IO.
What this hints at is a difference in the sector size between the disks on the primary and those on the secondary server (our new SAN).
Check Disk Sector Size
The fist thing to do is to check the sector size of the disks, this is pretty straight forward. Run the following from a command line.
fsutil fsinfo ntfsinfo <drive letter or mount point location>

Notice that ‘Bytes per Physical Sector’ is showing 4096 on our old storage. Now lets try running the same thing against the new storage.
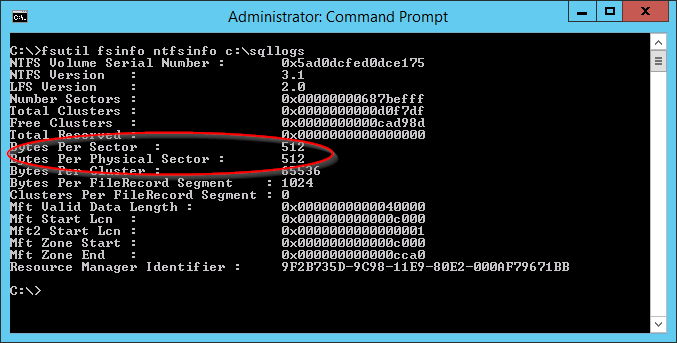
This time we can see that ‘Bytes per Physical Sector’ is 512. And there’s our mismatch.
Why Does This Cause a Problem?
When SQL Server writes a log entry, it checks the sector sizes of the disk and generates the log entry to match those sizes. In the case of an Availability Group (or Database Mirroring), this log entry is passed on to all its secondary servers.
The problem occurs when the secondary server notices that the log entry was generated for a disk with different sector sizes to what it’s got. It now has to do a little jiggery pokery to make the entry fit, this can cause it to switch to synchronous IO. As soon as this happens, we’ll see the error in the log that we’re getting.
How Does Synchronous IO Differ From Asynchronous IO
Usually, SQL Server will use Asynchronous IO. This basically means that a thread will throw something down to the storage subsystem and then get on with something else. It doesn’t bother waiting for a reply.
When SQL is forced to use synchronous IO, it will pass the request down but this time, the thread needs to wait for a reply from the storage subsystem before it can get on with anything else. And as we all know, storage is SLOWWWWWWW.
This can cause some really noticeable delays if you’re using Availability Groups and the secondary server happens to be configured as a synchronous secondary. Even if the server is an asynchronous secondary you could still get burnt. These delays could cause your secondaries to fall a long way behind your primary SQL Server, to the point where you could be looking at significant data loss and may struggle to meet your RPO if you’re ever forced to failover to that node (although I’d hope that you’ve got a decent backup strategy in place and aren’t relying solely on Availability Groups).
What To Do About It
For me, the fix was fairly simple. Switching the affected secondary to async (becareful here as this could affect your resiliency) was able to temporarily mitigate the issue for the users and the completion of the SAN migration solved the problem once and for all as all servers now have the same disk configuration.
If you’re not lucky enough to be in the middle of a migration and you’re stuck with the storage that you’re on, you might need to look into changing the sector sizes. Methods could vary depending on your storage and to be honest with you, in my case would be something that I’d throw at the storage team.
Traceflag 1800
If you can’t fix the disks themselves, traceflag 1800 may help you. I’ll be honest, I’ve never actually tested this yet (I need to spin up something on my test lab to see how it behaves) but according to Microsoft…
Enables SQL Server optimization when disks of different sector sizes are used for primary and secondary replica log files, in SQL Server Always On and Log Shipping environments. This trace flag is only required to be enabled on SQL Server instances with transaction log file residing on disk with sector size of 512 bytes. It is not required to be enabled on disk with 4k sector sizes. For more information, see this Microsoft Support article.
https://docs.microsoft.com/en-us/sql/t-sql/database-console-commands/dbcc-traceon-trace-flags-transact-sql?view=sql-server-2017

Hi, Did you test this in your lab environment?
I’m looking for the possible impact on a production environment, or how to monitor if something is going wrong after enabling this Trace Flag.
Could you share more information if you have about the possible “side-affects”
With kind regards,
Mitchel
LikeLike
I’ve proved the concept but I’ve not used it in anger or put any real load through it so wouldn’t want to comment on how it’d behave in production. If you’re thinking of using this with an AG setup, if possible I probably want to test it on an asynchronous node first and watch for any latency in synchronisation.
LikeLike