It wasn’t until the other day that I realised what the behaviour was when rolling back a transaction with an insert on a table with an identity column, to be fair I have never had a need to do so but I know that there are people who like to run code like below to validate before and after changes for updates for example:
BEGIN TRAN --Before Update SELECT ID, LogDate FROM [IdentityTest] WHERE LogDate <= DATEADD(DAY,-3,GETDATE()); UPDATE [IdentityTest] SET LogDate = GETDATE() WHERE LogDate <= DATEADD(DAY,-3,GETDATE()); --After Update SELECT ID, LogDate FROM [IdentityTest] WHERE LogDate <= DATEADD(DAY,-3,GETDATE()); --ROLLBACK TRAN --COMMIT TRAN
In the example above the user will see the data prior to the update and after the update and depending on whether they are happy with the results or not they either Commit or rollback.
This is certainly not a way in which I would recommend making updates,especially if you value concurrency as people tend to forget they have transactions open 🙂 .
As I say – This is just what I has seen people do and it was only the other day when I saw a similar situation but with an insert instead, The user believed that because the changes were made within a transaction this would rollback EVERYTHING however they did not consider the impact on the Identity column on the table they made the insert in.
Here is an example to demonstrate how a rollback on an insert will not rollback your identity seed on your table.
First I will create a demo table in my DBA database:
USE [DBA];
GO
IF OBJECT_ID('dbo.IdentityTest') IS NULL
BEGIN
CREATE TABLE [IdentityTest](
ID INT IDENTITY(1,1),
LogDate DATETIME
);
END
Check the current Identity value and show that there is currently no data:
--Check current Ident
SELECT IDENT_CURRENT('IdentityTest');
--Check data
SELECT
ID,
LogDate
FROM [IdentityTest];
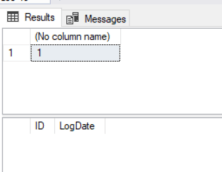
So the current identity seed is 1 and we have no data , nothing unusual there.
Lets Insert a row inside of a transaction and rollback the change, to illustrate the before and after effects during the transaction I will include before and after sql statements too.
BEGIN TRAN --Before Insert SELECT ID, LogDate FROM [IdentityTest]; INSERT INTO [IdentityTest] (LogDate) VALUES (GETDATE()); --After Insert SELECT ID, LogDate FROM [IdentityTest]; ROLLBACK TRAN

We can see from the above screenshot that during the transaction there were no rows until we made the insert and then we rolled the transaction back, just to prove that the insert was rolled back here is the data now.
SELECT ID, LogDate FROM [IdentityTest];
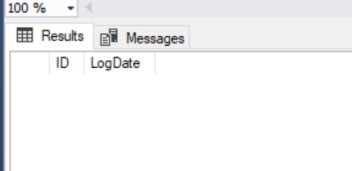
No rows as expected, so what about the Identity lets check to see if that rolled back too.
--Check current Ident
SELECT IDENT_CURRENT('IdentityTest');
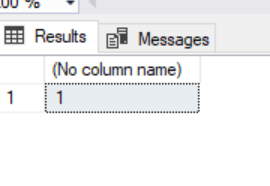
Result: 1 so on the face of it this looks sound! lets try making an actual insert this time then immediately check IDENT_CURRENT and the data in the table.
--Make an insert INSERT INTO [IdentityTest] (LogDate) VALUES (GETDATE()); --Check current Ident SELECT SCOPE_IDENTITY(); --check the data SELECT ID, LogDate FROM [IdentityTest];
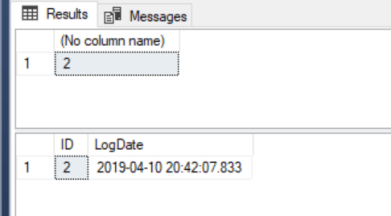
Interesting! this inserted ID 2 even though ID 1 does not exist and we thought we rolled it back!
So lets test this out by spinning through a bunch of inserts and rolling back all the even iterations, I have dropped and recreated the table for this test.
DECLARE @Iteration INT = 1 WHILE @Iteration < 50 BEGIN BEGIN TRAN INSERT INTO [IdentityTest] (LogDate) VALUES (GETDATE()); IF @Iteration%2 = 0 BEGIN ROLLBACK TRAN END ELSE BEGIN COMMIT TRAN END SET @Iteration += 1; END SELECT ID, LogDate FROM [IdentityTest];

The first thing I would assume if I saw gaps in the ID like this would be that someone deleted some data but I would never have even considered that its possible to cause the same gaps by rolling back an insert.
Whilst I did say in the title that its a bad idea to rollback inserts on tables with identity columns that’s only really if the Identity column actually has a real use other than just to make rows unique, in some cases the gaps may not even have an impact but certainly something to be aware of 🙂
Thanks for reading.

Specifically in SQL 2012, there was also a peculiar issue where, if you restarted the SQL Server service, you would suddenly get identity gap jumps of 1000 or 10000 values. This was because identity values were cached somehow in memory and then lost when the SQL service was stopped.
In any case, a while ago I’ve written a blog post and a generic TSQL script for “re-aligning” identity values with actual table values. You can find it here:
https://eitanblumin.com/2018/11/06/re-align-identity-last-value-to-actual-max-value/
LikeLiked by 1 person
Hi Eitan, didn’t know about that issue with SQL2012. Thank you for sharing!
LikeLike
Thanks this is interesting as I would have expected the rollback to roll everything back including resetting the sequence.
When creating a sequence in SQL Server you can specify the cache and this cache is lost when the instance is restarted so it skips forward by the number cached minus the number it is up to:
CREATE SEQUENCE SEQ_CountBy1Cache20
START WITH 1
INCREMENT BY 1
CACHE 20
LikeLike
Another interesting variation on the use of identity columns is that the order of the IDENTITY column isn’t necessarily the order in which the change was committed to the transaction log.
The reason for this is that sql server:
1. calculates the values for all columns in your row(s) that are about to be inserted (including any default/identitities)
2. using the values of those columns, goes and requests locks (IX) on any required objects (the clustered key, non clustered indexes, page, etc..)
3. when the locks have been granted, then the change is committed.
For most people this is never a real problem, but it can show up as odd behaviour if you are consuming the just written rows (using the identity as your key for which rows you have already consumed) or if you are processing data from replication/log shipped results, where it looks like the last n records have gaps in their IDs.
LikeLike
A very interesting point indeed! Thanks for sharing Andrew!
LikeLike
This is related to concurrency. Would you want a thread to have to wait for all transactions relating to that table to have to commit or rollback before you can insert another row? That would effectively mean that all work relating to that table is single-threaded.
The “Bad idea” is expecting identity values to be strictly sequential.
LikeLike